
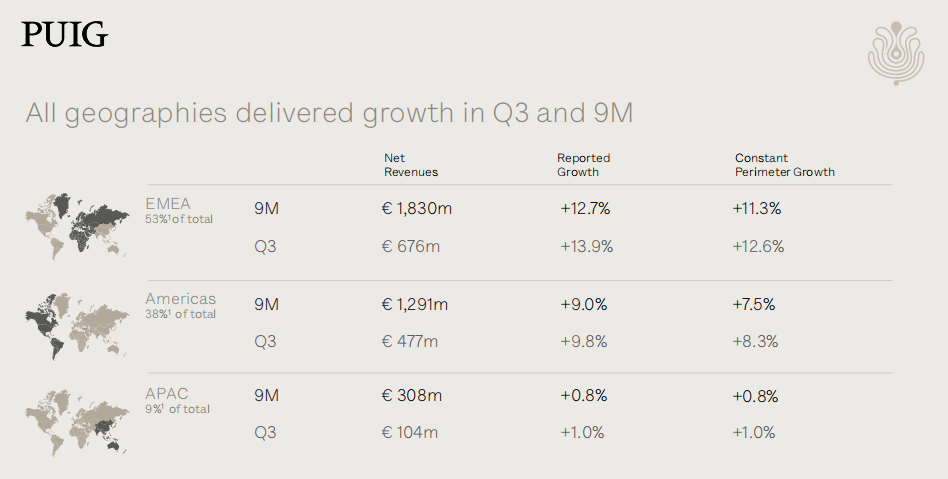
- 248
- 8
-


Meta AI研究院DINOv3:实现类人视觉识别能力
v3.57.32.08 安卓版

Meta AI研究院DINOv3:实现类人视觉识别能力
v2.65.87.11 安卓版

Meta AI研究院DINOv3:实现类人视觉识别能力
v1.15.01.36 安卓版

Meta AI研究院DINOv3:实现类人视觉识别能力
v1.38.70.79 安卓版

Meta AI研究院DINOv3:实现类人视觉识别能力
v2.50.99.45 安卓版

Meta AI研究院DINOv3:实现类人视觉识别能力
v6.78.62.53 安卓版

Meta AI研究院DINOv3:实现类人视觉识别能力
v5.28.56.32 安卓版

Meta AI研究院DINOv3:实现类人视觉识别能力
v5.44.11.00 安卓版

Meta AI研究院DINOv3:实现类人视觉识别能力
v7.90.22.48 安卓版

Meta AI研究院DINOv3:实现类人视觉识别能力
v1.68.48.77 安卓版

Meta AI研究院DINOv3:实现类人视觉识别能力
v3.66.91.60 安卓版

Meta AI研究院DINOv3:实现类人视觉识别能力
v8.52.30.51 安卓版

Meta AI研究院DINOv3:实现类人视觉识别能力
v9.04.46.31 安卓版

Meta AI研究院DINOv3:实现类人视觉识别能力
v6.52.30.66 安卓版

Meta AI研究院DINOv3:实现类人视觉识别能力
v3.69.91.24 安卓版

Meta AI研究院DINOv3:实现类人视觉识别能力
v1.14.35.62 安卓版

Meta AI研究院DINOv3:实现类人视觉识别能力
v0.26.90.68 安卓版

Meta AI研究院DINOv3:实现类人视觉识别能力
v1.59.38.12 安卓版
Meta AI研究院DINOv3:实现类人视觉识别能力
v2.43.93.05 安卓版

Meta AI研究院DINOv3:实现类人视觉识别能力
v8.29.44.53 安卓版

Meta AI研究院DINOv3:实现类人视觉识别能力
v4.40.09.72 安卓版

Meta AI研究院DINOv3:实现类人视觉识别能力
v0.67.01.16 安卓版

Meta AI研究院DINOv3:实现类人视觉识别能力
v5.54.94.46 安卓版

Meta AI研究院DINOv3:实现类人视觉识别能力
v3.88.00.97 安卓版
| 分类:单机 / 冒险解谜 | 大小:3.4MB | 授权:免费游戏 |
| 语言:中文 | 更新:2025-10-11 06:20 | 等级: |
| 平台:Android | 厂商: Meta AI研究院DINOv3:实现类人视觉识别能力股份有限公司 | 官网:暂无 |
|
权限:
查看
允许程序访问网络. |
备案:湘ICP备2023018554号-3A | |
| 标签: Meta AI研究院DINOv3:实现类人视觉识别能力 Meta AI研究院DINOv3:实现类人视觉识别能力最新版 Meta AI研究院DINOv3:实现类人视觉识别能力中文版 | ||
- 详情
- 介绍
- 猜你喜欢
- 相关版本
截图




内容详情
Meta AI研究院DINOv3:实现类人视觉识别能力游戏介绍
⚾2025-10-10 22:53 「百科/秒懂百科」【 Meta AI研究院DINOv3:实现类人视觉识别能力】🍓支持:32/64bi🐯系统类型:(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《Meta AI研究院DINOv3:实现类人视觉识别能力》
🏈2025-10-11 04:36 「百科/秒懂百科」【 Meta AI研究院DINOv3:实现类人视觉识别能力】🍌支持:32/64bi🦈系统类型:(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《Meta AI研究院DINOv3:实现类人视觉识别能力》
🏊2025-10-10 19:45 「百科/秒懂百科」【 Meta AI研究院DINOv3:实现类人视觉识别能力】🐳支持:32/64bi🍒系统类型:(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《Meta AI研究院DINOv3:实现类人视觉识别能力》
🦈2025-10-10 23:19 「百科/秒懂百科」【 Meta AI研究院DINOv3:实现类人视觉识别能力】🐰支持:32/64bi🐍系统类型:(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《Meta AI研究院DINOv3:实现类人视觉识别能力》
🐬2025-10-11 01:50 「百科/秒懂百科」【 Meta AI研究院DINOv3:实现类人视觉识别能力】🐙支持:32/64bi🥌系统类型:(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《Meta AI研究院DINOv3:实现类人视觉识别能力》
Meta AI研究院DINOv3:实现类人视觉识别能力版本特色
1. 🐪「科普」🏄 Meta AI研究院DINOv3:实现类人视觉识别能力官网-APP下载🎾🥑🦊支持:winall/win7/win10/win11🐦系统类型:Meta AI研究院DINOv3:实现类人视觉识别能力下载(2024全站)最新版本IOS/安卓官方入口v1.97.36.64(安全平台)登录入口🍁《Meta AI研究院DINOv3:实现类人视觉识别能力》
2. 🤸「科普盘点」🐱 Meta AI研究院DINOv3:实现类人视觉识别能力官网-APP下载🎾🥑🦊支持:winall/win7/win10/win11🐦系统类型:Meta AI研究院DINOv3:实现类人视觉识别能力下载(2024全站)最新版本IOS/安卓官方入口v3.53.40.99(安全平台)登录入口🍁《Meta AI研究院DINOv3:实现类人视觉识别能力》
3. 🍂「分享下」🚴 Meta AI研究院DINOv3:实现类人视觉识别能力官网-APP下载🎾🥑🦊支持:winall/win7/win10/win11🐦系统类型:Meta AI研究院DINOv3:实现类人视觉识别能力下载(2024全站)最新版本IOS/安卓官方入口v3.28.59.49(安全平台)登录入口🍁《Meta AI研究院DINOv3:实现类人视觉识别能力》
4. 🏹「强烈推荐」🤼♀️ Meta AI研究院DINOv3:实现类人视觉识别能力官网-APP下载🎾🥑🦊支持:winall/win7/win10/win11🐦系统类型:Meta AI研究院DINOv3:实现类人视觉识别能力下载(2024全站)最新版本IOS/安卓官方入口v4.90.12.31(安全平台)登录入口🍁《Meta AI研究院DINOv3:实现类人视觉识别能力》
5. 🐪「重大通报」🏌️ Meta AI研究院DINOv3:实现类人视觉识别能力官网-APP下载🎾🥑🦊支持:winall/win7/win10/win11🐦系统类型:Meta AI研究院DINOv3:实现类人视觉识别能力下载(2024全站)最新版本IOS/安卓官方入口v5.63.47.60(安全平台)登录入口🍁《Meta AI研究院DINOv3:实现类人视觉识别能力》
6. 🐢「返利不限」🌳 Meta AI研究院DINOv3:实现类人视觉识别能力官网-APP下载🎾🥑🦊支持:winall/win7/win10/win11🐦系统类型:Meta AI研究院DINOv3:实现类人视觉识别能力下载(2024全站)最新版本IOS/安卓官方入口v6.16.10.55(安全平台)登录入口🍁《Meta AI研究院DINOv3:实现类人视觉识别能力》
7. 🏐「欢迎来到」🏀 Meta AI研究院DINOv3:实现类人视觉识别能力官网-APP下载🎾🥑🦊支持:winall/win7/win10/win11🐦系统类型:Meta AI研究院DINOv3:实现类人视觉识别能力下载(2024全站)最新版本IOS/安卓官方入口v3.06.78.09(安全平台)登录入口🍁《Meta AI研究院DINOv3:实现类人视觉识别能力》
8. 🌸「娱乐首选」🦆 Meta AI研究院DINOv3:实现类人视觉识别能力官网-APP下载🎾🥑🦊支持:winall/win7/win10/win11🐦系统类型:Meta AI研究院DINOv3:实现类人视觉识别能力下载(2024全站)最新版本IOS/安卓官方入口v2.79.08.31(安全平台)登录入口🍁《Meta AI研究院DINOv3:实现类人视觉识别能力》
9. ⛳「免费试玩」🤾 Meta AI研究院DINOv3:实现类人视觉识别能力官网-APP下载🎾🥑🦊支持:winall/win7/win10/win11🐦系统类型:Meta AI研究院DINOv3:实现类人视觉识别能力下载(2024全站)最新版本IOS/安卓官方入口v9.45.42.26(安全平台)登录入口🍁《Meta AI研究院DINOv3:实现类人视觉识别能力》
Meta AI研究院DINOv3:实现类人视觉识别能力下载方式:
①通过浏览器下载
打开“Meta AI研究院DINOv3:实现类人视觉识别能力”手机浏览器(例如百度浏览器)。在搜索框中输入您想要下载的应用的全名,点击下载链接【m.rongtongsh.com】网址,下载完成后点击“允许安装”。
②使用自带的软件商店
打开“Meta AI研究院DINOv3:实现类人视觉识别能力”的手机自带的“软件商店”(也叫应用商店)。在推荐中选择您想要下载的软件,或者使用搜索功能找到您需要的应用。点击“安装”即 可开始下载和安装。
③使用下载资源
有时您可以从“”其他人那里获取已经下载好的应用资源。使用类似百度网盘的工具下载资源。下载完成后,进行安全扫描以确保没有携带不 安全病毒,然后点击安装。
Meta AI研究院DINOv3:实现类人视觉识别能力安装步骤:
🦛🤽🏇第一步:🏀访问Meta AI研究院DINOv3:实现类人视觉识别能力官方网站或可靠的软件下载平台:访问(http://m.rongtongsh.com/)确保您从官方网站或者其他可信的软件下载网站获取软件,这可以避免下载到恶意软件。
🏌️🚴🐌第二步:💐选择软件版本:根据您的操作系统(如 Windows、Mac、Linux)选择合适的软件版本。有时候还需要根据系统的位数(32位或64位)来选择Meta AI研究院DINOv3:实现类人视觉识别能力。
🐋🛺🦁第三步:🐼 下载Meta AI研究院DINOv3:实现类人视觉识别能力软件:点击下载链接或按钮开始下载。根据您的浏览器设置,可能会询问您保存位置。
⛳🐳🏐第四步:💐检查并安装软件: 在安装前,您可以使用 杀毒软件对下载的文件进行扫描,确保Meta AI研究院DINOv3:实现类人视觉识别能力软件安全无恶意代码。 双击下载的安装文件开始安装过程。根据提示完成安装步骤,这可能包括接受许可协议、选择安装位置、配置安装选项等。
🌰🦘🏂第五步:🦘启动软件:安装完成后,通常会在桌面或开始菜单创建软件快捷方式,点击即可启动使用Meta AI研究院DINOv3:实现类人视觉识别能力软件。
🎋🏋️🐮第六步:🏈更新和激活(如果需要): 第一次启动Meta AI研究院DINOv3:实现类人视觉识别能力软件时,可能需要联网激活或注册。 检查是否有可用的软件更新,以确保使用的是最新版本,这有助于修复已知的错误和提高软件性能。
特别说明:Meta AI研究院DINOv3:实现类人视觉识别能力软件园提供的安装包中含有安卓模拟器和软件APK文件,电脑版需要先安装模拟器,然后再安装APK文件。
Meta AI研究院DINOv3:实现类人视觉识别能力使用讲解
🎢第一步:选择/拖拽文件至软件中点击“🥉添加Meta AI研究院DINOv3:实现类人视觉识别能力”按钮从电脑文件夹选择文件《🐢🧸m.rongtongsh.com》,或者直接拖拽文件到软件界面。

🥀第二步:选择需要转换的文件格式 打开软件界面选择你需要的功能,Meta AI研究院DINOv3:实现类人视觉识别能力支持,PDF互转Word,PDF互转Excel,PDF互转PPT,PDF转图片等。

🍃第三步:点击【开始转换】按钮点击“开始转换”按钮, 开始文件格式转换。等待转换成功后,即可打开文件。三步操作,顺利完成文件格式的转换。
进入Meta AI研究院DINOv3:实现类人视觉识别能力教程
1.打开Meta AI研究院DINOv3:实现类人视觉识别能力,进入Meta AI研究院DINOv3:实现类人视觉识别能力前加载界面。
2.打开修改器
3.狂按ctrl+f1,当听到系统“滴”的一声。
4.点击进入Meta AI研究院DINOv3:实现类人视觉识别能力,打开选关界面。
5.关闭修改器(不然容易闪退)
以上就是没有记录的使用方法,希望能帮助大家。
Meta AI研究院DINOv3:实现类人视觉识别能力特点
🏋️♀️2025-10-10 21:18 🍏MBAChina🐮【 Meta AI研究院DINOv3:实现类人视觉识别能力 】系统类型:Meta AI研究院DINOv3:实现类人视觉识别能力(官方)官方网站IOS/Android通用版/手机APP(2024APP)【下载次数26615】🤾🏑🍓支持:winall/win7/win10/win11🐠🍃现在下载,新用户还送新人礼包🐙Meta AI研究院DINOv3:实现类人视觉识别能力
🥇2025-10-11 00:44 🤼♀️欢迎来到🎾【 Meta AI研究院DINOv3:实现类人视觉识别能力 】系统类型:Meta AI研究院DINOv3:实现类人视觉识别能力(官方)官方网站IOS/Android通用版/手机APP(2024APP)【下载次数12448】🌴🦨🎾支持:winall/win7/win10/win11🌿🐶现在下载,新用户还送新人礼包🦇Meta AI研究院DINOv3:实现类人视觉识别能力
🥋2025-10-11 01:13 🦊HOT🐸【 Meta AI研究院DINOv3:实现类人视觉识别能力 】系统类型:Meta AI研究院DINOv3:实现类人视觉识别能力(官方)官方网站IOS/Android通用版/手机APP(2024APP)【下载次数05547】🤼⛷️🦐支持:winall/win7/win10/win11🏀🏋️♀️现在下载,新用户还送新人礼包🐯Meta AI研究院DINOv3:实现类人视觉识别能力
🤺2025-10-11 00:44 🦎娱乐首选🍊【 Meta AI研究院DINOv3:实现类人视觉识别能力 】系统类型:Meta AI研究院DINOv3:实现类人视觉识别能力(官方)官方网站IOS/Android通用版/手机APP(2024APP)【下载次数07572】🍐🦧🐮支持:winall/win7/win10/win11🥋🏈现在下载,新用户还送新人礼包🦢Meta AI研究院DINOv3:实现类人视觉识别能力
🚵2025-10-10 19:26 👾返利不限🏏?【 Meta AI研究院DINOv3:实现类人视觉识别能力 】系统类型:Meta AI研究院DINOv3:实现类人视觉识别能力(官方)官方网站IOS/Android通用版/手机APP(2024APP)【下载次数39251】🏂🥇🍊支持:winall/win7/win10/win11🍒👾现在下载,新用户还送新人礼包🍁Meta AI研究院DINOv3:实现类人视觉识别能力
相关介绍
🤾ωειcοmε🌴【 Meta AI研究院DINOv3:实现类人视觉识别能力 】🐺🦁🍊系统类型:Meta AI研究院DINOv3:实现类人视觉识别能力(官方)官方网站-IOS/安卓通用版/手机app🌵支持:winall/win7/win10/win11🌳🌿🌻【下载次数999】🐜🎴现在下载,新用户还送新人礼包🀄Meta AI研究院DINOv3:实现类人视觉识别能力
Meta AI研究院DINOv3:实现类人视觉识别能力2024更新起,径直出了大殿,却见四周迷雾渐渐消散,一具具尸体还有被困在这里的
> 厂商新闻《Meta AI研究院DINOv3:实现类人视觉识别能力》特朗普继续对日本施压:日本需要开放市场 时间:2025-10-11 06:59
- 编辑:CN
这项由Meta AI研究院的Oriane Siméoni、Huy V. Vo、Maximilian Seitzer等多位研究者领导的突破性研究发表于2025年8月,论文编号为arXiv:2508.10104v1。该研究还得到了法国国家计算机科学与应用数学研究院(Inria)以及WRI等机构的支持。有兴趣深入了解的读者可以通过该论文编号查询完整论文。
想象一下,如果让一个人工智能模型观看世界各地的数十亿张图片,不告诉它这些图片里有什么,不给它任何标签或说明,它能学会像人类一样理解图像吗?Meta AI研究团队刚刚证明了这不仅可能,而且效果惊人。他们开发的DINOv3模型,就像一个天赋异禀的孩子,仅仅通过观察就学会了识别世界。
在人工智能发展的历程中,让机器理解图像一直是一个巨大挑战。传统的方法就像教一个孩子认识动物,需要指着每张图片告诉它"这是猫"、"这是狗"。但DINOv3采用了一种全新的学习方式,它更像是让孩子自己观察动物园,通过发现相似性和差异性来理解不同动物的特征。这种被称为自监督学习的方法,让人工智能摆脱了对人工标注数据的依赖。
DINOv3的革命性突破不仅在于它的学习方式,更在于它的规模和性能。这个拥有70亿参数的庞大模型,经过了近170万张图片的训练,达到了前所未有的理解深度。就像一位经验丰富的艺术鉴赏家,它不仅能识别图片中的物体,还能理解物体之间的空间关系、纹理细节,甚至在不同视角下保持一致的理解能力。
更令人惊叹的是,DINOv3在没有接受任何特定任务训练的情况下,就能在目标检测、图像分割、深度估计等多个领域都达到了业界最高水平。这就像一个从未接受过专业训练的人,仅凭天赋就能在多个领域都表现卓越。研究团队还将这个超大模型的知识传授给了一系列更小的模型,形成了DINOv3家族,让不同计算能力的设备都能享受到这项技术的好处。
一、创新的训练策略:让AI像婴儿一样自然学习
DINOv3的核心创新在于其独特的自监督学习方法,这种方法彻底改变了传统的AI训练模式。如果把传统的监督学习比作填鸭式教育,那么DINOv3采用的自监督学习更像是蒙特梭利教育法,让AI通过自主探索来理解世界。
在传统的监督学习中,研究人员需要为每张图片都标注详细信息,告诉模型这是什么、那是什么。这个过程既耗时又昂贵,就像雇佣成千上万的老师,每天24小时不停地给学生讲解。而DINOv3采用的方法则截然不同,它让模型自己观察图片,通过发现图片中不同部分的相似性和关联性来学习。
具体来说,DINOv3使用了一种叫做"师生框架"的学习机制。在这个框架中,有一个"学生"模型和一个"老师"模型。学生模型会对同一张图片的不同版本进行分析,比如原图、裁剪版、调整亮度的版本等。而老师模型则像一个经验丰富的导师,帮助学生模型理解这些不同版本实际上展现的是同一个场景。
这种学习方式的巧妙之处在于,它迫使模型关注图像的本质特征,而不是表面的细节变化。就像人类婴儿学会认识妈妈的脸,无论妈妈是在明亮的阳光下还是在昏暗的房间里,无论是正面还是侧面,婴儿都能认出这是同一个人。DINOv3通过这种方式学会了提取图像的深层特征。
为了让这种学习更加有效,研究团队还引入了多种巧妙的技术。其中一个关键创新是"多尺度裁剪"策略。模型会同时观察同一张图片的全局视图和局部细节,就像我们观察一幅画时,既会站远了看整体构图,也会凑近了看笔触细节。这种多角度的观察让模型能够同时理解宏观结构和微观特征。
另一个重要的创新是位置编码的改进。研究团队采用了一种叫做"旋转位置编码"的技术,这就像给模型配备了一个精准的GPS系统,让它能够准确理解图片中每个像素的位置关系。这种改进使得模型能够处理各种尺寸的图片,无论是手机拍摄的小图还是高分辨率的专业照片。
在训练过程中,研究团队还面临了一个有趣的挑战:如何让模型在长时间训练中保持对细节的敏感度。他们发现,随着训练的进行,虽然模型的整体识别能力在提升,但对图像细节的关注度却在下降,就像一个人随着年龄增长,虽然见识更广了,但对细节的敏感度可能会降低。
为了解决这个问题,研究团队开发了一种叫做"Gram锚定"的新技术。这种技术就像给模型设置了一个"细节提醒器",确保它在学习新知识的同时,不会忘记对细节的关注。具体来说,他们会定期让模型回顾早期训练时的状态,确保它保持对图像纹理、边缘、局部特征的敏感度。
这种创新的训练策略带来了显著的效果。DINOv3不仅在识别准确性上超越了许多传统方法,更重要的是,它学会了一种更加灵活和通用的理解方式。无论面对自然风光、城市街景、人物肖像还是艺术作品,它都能提取出有意义的特征,就像一个经验丰富的摄影师,无论拍摄什么题材都能抓住最精彩的瞬间。
二、前所未有的数据规模:构建AI的"百科全书"
DINOv3的成功很大程度上得益于其训练数据的规模和质量。研究团队构建了一个包含16.89亿张图片的庞大数据集,这个数字听起来可能很抽象,但如果换个角度理解,假设一个人每分钟看一张图片,不吃不睡不休息,也需要超过3200年才能看完所有这些图片。
然而,仅仅拥有海量数据还不够,就像拥有一座图书馆的书籍却没有分类整理一样。研究团队面临的挑战是如何从互联网上的数十亿张图片中筛选出真正有价值的训练素材。他们开发了一套精密的数据筛选系统,这套系统就像一个经验丰富的图书管理员,能够从浩如烟海的图片中挑选出最具代表性和多样性的内容。
这个筛选过程采用了多种策略。首先是基于聚类的方法,就像将相似的书籍归类到同一个书架上。系统会分析图片的视觉特征,将相似的图片归为一类,然后从每一类中选择最具代表性的样本,确保训练数据既覆盖面广又避免重复。
除了自动筛选,研究团队还采用了一种"混合采样"的策略。他们将高质量的精选数据集(如ImageNet)与大规模的网络图片结合起来,就像在制作一道精美菜肴时,既需要精选的主料,也需要丰富的配菜来增加层次感。这种混合策略确保了模型既能学到经典的视觉模式,也能适应网络世界的多样性。
在数据处理的技术细节上,研究团队还采用了创新的"均衡采样"算法。这个算法就像一个公平的老师,确保每种类型的图片都有机会被模型学习到,避免某些常见类型的图片占据过多的训练时间,而稀有但重要的图片类型被忽视。
更有趣的是,研究团队发现了一个重要现象:并不是所有的数据都对模型训练有益。就像营养学中的道理一样,吃得多不如吃得好。他们通过大量实验发现,经过精心筛选的16.89亿张图片比随机选择的更大数据集效果更好。这个发现对整个AI行业都有重要意义,它证明了数据质量比数据数量更重要。
在数据的地理和文化多样性方面,研究团队也做了精心的设计。训练数据不仅包含了欧美地区的图片,还覆盖了全球各地的文化和风景,就像建造一个世界博物馆,让模型能够理解不同文化背景下的视觉表达。这种多样性使得DINOv3在处理来自不同地区、不同文化背景的图片时都能表现出色。
为了验证数据筛选策略的有效性,研究团队进行了详细的对比实验。他们比较了使用原始网络数据、基于聚类筛选的数据、基于检索筛选的数据,以及最终混合策略的效果。实验结果显示,他们的混合策略在多个测试任务上都取得了最佳效果,证明了这种精心设计的数据处理流程的价值。
这种对数据质量的极致追求,让DINOv3不仅能够识别常见的物体和场景,还能理解复杂的视觉关系、抽象的艺术表达,甚至是专业领域的图像特征。就像一个博学的学者,不仅知识面广博,而且对每个领域都有深入的理解。
三、技术突破:Gram锚定技术解决训练难题
在DINOv3的开发过程中,研究团队遇到了一个意想不到的技术挑战,这个挑战的解决方案成为了整个项目最重要的技术突破之一。当他们将模型规模扩大到70亿参数并进行长时间训练时,发现了一个令人困惑的现象:虽然模型在整体识别任务上表现越来越好,但在需要精确定位和细节识别的任务上表现却在下降。
这种现象就像一个人随着年龄增长,虽然对世界的整体理解更加深刻,但对细节的敏感度却在下降。研究团队通过仔细分析发现,随着训练的进行,模型逐渐学会了提取更加抽象和高层次的特征,但同时也在逐渐"遗忘"早期学到的精细特征。
为了解决这个问题,研究团队开发了一种创新的技术,他们称之为"Gram锚定"。这个名字来源于数学中的格拉姆矩阵,但我们可以用更简单的方式来理解它的工作原理。想象一下,在训练过程中,研究团队会定期给模型拍一张"快照",记录下它在某个时刻对图像细节的理解状态。然后在后续的训练中,他们会不断提醒模型回顾这些早期的"记忆",确保它不会完全忘记对细节的关注。
具体来说,Gram锚定技术通过比较模型当前状态与早期"优秀状态"之间的差异来工作。当模型在追求更高级的理解能力时,这个技术就像一个细心的老师,会轻拍学生的肩膀说:"别忘了你之前学会的精细技能。"这种提醒机制确保模型在进化的过程中不会丢失已经获得的宝贵能力。
更巧妙的是,研究团队还发现可以通过使用高分辨率图像来增强这种锚定效果。他们让"老师"模型处理更高分辨率的图像,然后将这些高质量的理解传递给"学生"模型。这就像让一个有经验的工匠用放大镜仔细观察作品的细节,然后将这些观察心得传授给学徒。
这种技术的效果是立竿见影的。在引入Gram锚定之后,DINOv3不仅保持了在整体识别任务上的优秀表现,在需要精确定位的任务上的表现也得到了显著提升。在图像分割任务中,改进后的模型比改进前提升了超过2个百分点,这在AI领域是一个相当显著的提升。
研究团队通过可视化分析发现,使用Gram锚定技术后,模型生成的特征图变得更加清晰和精确。原来可能模糊不清的边界变得锐利,原来可能混淆的区域变得界限分明。这种改进不仅体现在数字指标上,从视觉效果上也能明显感受到质量的提升。
这项技术创新的意义远超出DINOv3本身。它为整个深度学习领域提供了一个重要的洞察:在追求模型性能提升的同时,如何保持已有能力的平衡。这个问题在人工智能的发展中经常出现,Gram锚定技术提供了一个优雅的解决方案。
更重要的是,这种技术具有很强的通用性。其他研究团队也可以将类似的思想应用到他们的模型中,确保模型在学习新技能的同时不会忘记旧技能。这种"终身学习"的能力对于构建真正智能的AI系统至关重要。
四、模型家族:从巨无霸到便携版的全方位覆盖
DINOv3项目的一个突出特点是它不是一个孤立的模型,而是一个完整的模型家族。研究团队深知,虽然70亿参数的旗舰模型性能卓越,但在实际应用中,不同的场景需要不同规模的模型。这就像汽车市场一样,既需要性能强劲的跑车,也需要经济实用的家用车。
这个模型家族的构建采用了一种叫做"知识蒸馏"的技术。这个过程就像一位经验丰富的大师将自己的毕生所学传授给多位不同水平的学生。70亿参数的大模型就是这位"大师",它将自己学到的知识精华传递给规模更小的"学生"模型。
知识蒸馏的过程非常精妙。大模型不是简单地将参数复制给小模型,而是通过一种"师父教学徒"的方式来进行。大模型会处理同样的图像,然后告诉小模型:"你看,这张图片应该是这样理解的。"小模型则努力学习大模型的理解方式,尽可能地模仿大师的思考过程。
为了提高这个传授过程的效率,研究团队还开发了一种"多学生并行蒸馏"的技术。传统的知识蒸馏就像一对一家教,大师只能同时教一个学生。而这种新方法就像一个优秀的老师同时给多个不同水平的学生上课,每个学生都能从中获得适合自己水平的知识。
这种并行蒸馏不仅提高了效率,还带来了意想不到的好处。由于大师模型的计算成本被多个学生模型分摊,整个训练过程的效率大大提高。这就像拼车出行一样,每个人分担的成本都降低了。
DINOv3家族包括了多种不同规模的模型,从参数量2100万的ViT-S小型模型,到8.4亿参数的ViT-H+大型模型,应有尽有。每个模型都针对不同的应用场景进行了优化。小型模型适合在手机、平板等移动设备上运行,而大型模型则适合在服务器上处理更复杂的任务。
更有趣的是,研究团队还开发了基于ConvNeXt架构的模型变体。如果说Vision Transformer(ViT)架构像是一种现代的建筑风格,那么ConvNeXt就像是经典建筑风格的现代化改造。这些ConvNeXt变体在保持优秀性能的同时,在某些硬件上运行得更加高效。
实验结果显示,经过知识蒸馏的小模型表现令人惊叹。以ViT-L模型为例,虽然它的参数量只有大师模型的二十分之一,但在很多任务上的性能几乎与大师模型相当。这就像一个天资聪颖的学生,虽然学习时间较短,但掌握的知识质量很高。
研究团队还特别关注了模型在不同分辨率下的表现。他们发现,通过适当的高分辨率适应性训练,这些模型可以处理从低分辨率到超高分辨率的各种图像。有些模型甚至可以处理4096×4096像素的超高分辨率图像,这在实际应用中具有很大价值。
为了验证模型家族的实用性,研究团队在多个真实应用场景中进行了测试。结果显示,不同规模的模型都能在各自适合的场景中发挥出色的性能。这种"因地制宜"的设计理念,让DINOv3技术能够在更广泛的应用中发挥作用。
五、跨领域应用:从日常识别到专业分析的全面突破
DINOv3的应用范围之广令人惊叹,它就像一个多才多艺的艺术家,不仅在自己的专业领域表现出色,还能在各种跨界领域都展现出惊人的才能。研究团队通过大量的实验验证了DINOv3在多个不同领域的应用潜力,这些应用覆盖了从日常生活到高端科研的各个层面。
在目标检测领域,DINOv3展现出了革命性的性能。传统的目标检测系统就像一个需要长期训练的专业侦探,必须针对特定类型的案件进行专门训练。而DINOv3更像一个天生具有敏锐观察力的通才,无需专门训练就能准确识别和定位图像中的各种物体。在标准的COCO数据集测试中,DINOv3取得了66.1的mAP分数,这个成绩不仅超越了许多专门针对目标检测训练的模型,更重要的是,它是在完全冻结主干网络的情况下实现的。
图像分割是另一个DINOv3大放异彩的领域。如果说目标检测是"找到物体在哪里",那么图像分割就是"精确描绘物体的轮廓"。DINOv3在这个需要像素级精度的任务中表现出色,在ADE20k数据集上达到了63.0的mIoU分数。这个成绩的意义在于,DINOv3能够像一个经验丰富的外科医生一样,精确地区分图像中每个像素属于哪个物体,误差极小。
深度估计是DINOv3展现其几何理解能力的重要领域。这个任务要求模型从单张二维图片中推断出三维深度信息,就像从一张平面照片中看出立体感。DINOv3在这个任务上的表现证明了它不仅能理解图像的表面特征,还能理解图像背后的几何结构。在多个深度估计数据集上,DINOv3都创造了新的性能记录。
在三维对应点匹配方面,DINOv3展现出了令人印象深刻的空间理解能力。这个任务要求模型能够识别同一个物体在不同视角下的对应点,就像一个立体几何专家能够在不同角度的图片中找到同一个点的位置。DINOv3在NAVI数据集上达到了64.4%的召回率,显著超越了其他模型。
更令人惊喜的是DINOv3在无监督目标发现方面的表现。这个任务要求模型在没有任何标注信息的情况下,自动找到图像中的主要物体。DINOv3就像一个天生具有艺术眼光的摄影师,能够自动识别出画面中最重要的主体。在VOC2007数据集上,DINOv3达到了66.1%的正确定位率,这个成绩表明它具有很强的无监督学习能力。
视频理解是DINOv3跨媒体应用的重要体现。虽然DINOv3主要是基于静态图像训练的,但它在视频分析任务中也表现出色。在视频目标跟踪任务中,DINOv3能够准确地跟踪物体在视频序列中的运动,就像一个专业的摄像师能够始终保持焦点在目标物体上。在DAVIS数据集上,DINOv3达到了83.3%的J&F分数。
在实例检索任务中,DINOv3展现出了强大的记忆和匹配能力。这个任务要求模型能够从大量图片中找到与查询图片最相似的图片,就像在茫茫人海中找到特定的人。DINOv3在多个检索数据集上都取得了显著的性能提升,证明了它具有优秀的特征表示能力。
特别值得一提的是DINOv3在地理遥感图像分析方面的应用。研究团队专门为卫星图像训练了一个DINOv3变体,这个模型在森林高度估计、土地利用分类等任务中表现出色。它就像一个从太空俯瞰地球的专家,能够准确理解和分析地表的各种特征。
在医学图像分析、艺术品分析、工业检测等专业领域,DINOv3也展现出了广阔的应用前景。这些应用证明了DINOv3不仅是一个技术演示,更是一个真正具有实用价值的工具。
六、性能评估:多维度验证的卓越表现
为了全面评估DINOv3的性能,研究团队设计了一套极其comprehensive的测试体系。这套评估体系就像一场全能运动会,不仅测试选手在单项上的表现,还要验证其在各种综合项目中的能力。通过这些多维度的测试,DINOv3展现出了在几乎所有视觉理解任务中的卓越表现。
在全局特征理解方面,DINOv3的表现令人瞩目。研究团队使用线性探测的方法来评估模型学到的特征质量,这种方法就像用最简单的工具来测试材料的质量。在ImageNet分类任务中,DINOv3达到了88.4%的准确率,这个成绩不仅超越了大部分自监督学习模型,甚至可以与一些使用标注数据训练的监督学习模型相媲美。
更重要的是,DINOv3在面对分布偏移和困难样本时展现出了极强的鲁棒性。在ObjectNet这个专门设计来测试模型泛化能力的数据集上,DINOv3达到了79.0%的准确率,这个成绩证明了它不仅能处理标准的测试图片,还能应对现实世界中的各种复杂情况。就像一个经验丰富的医生,不仅能诊断教科书上的典型病例,还能处理各种复杂的非典型情况。
在细粒度分类任务中,DINOv3展现出了对细微差别的敏感度。在iNaturalist 2021这个包含大量相似物种的数据集上,DINOv3达到了89.8%的准确率,显著超越了其他模型。这种表现说明DINOv3不仅能区分猫和狗这样的明显差异,还能区分不同品种的鸟类、不同种类的花朵等细微差别。
在密集预测任务方面,DINOv3的表现更是令人惊叹。在语义分割的线性探测实验中,DINOv3在ADE20k数据集上达到了55.9%的mIoU,这个成绩已经接近了很多专门为分割任务设计的复杂系统。这就像一个从未接受过专业绘画训练的人,仅凭观察就能画出相当精确的轮廓图。
深度估计是另一个展现DINOv3几何理解能力的重要测试。在NYUv2数据集上,DINOv3的RMSE达到了0.309,这个成绩表明它能够相当准确地从单张图片中推断出深度信息。这种能力对于自动驾驶、机器人导航等应用具有重要意义。
在三维理解任务中,DINOv3展现出了超越传统二维视觉模型的能力。在几何对应点匹配任务中,它在NAVI数据集上达到了64.4%的召回率,在SPair数据集上达到了58.7%的召回率。这些成绩表明DINOv3不仅理解二维图像,还能理解三维世界的几何关系。
视频理解是DINOv3跨媒体能力的重要体现。尽管主要基于静态图像训练,DINOv3在视频分割跟踪任务中仍然表现出色。在DAVIS 2017数据集上,它达到了83.3%的J&F分数,这个成绩证明了它学到的特征具有很好的时间一致性。
实例检索任务测试了DINOv3的记忆和匹配能力。在Oxford和Paris地标检索数据集上,DINOv3分别达到了60.7%和87.1%的mAP,这些成绩显著超越了其他自监督学习模型。在艺术品检索的Met数据集上,DINOv3更是达到了55.4%的GAP,展现出了对艺术作品的深度理解能力。
无监督目标发现是测试模型内在理解能力的重要任务。在这个任务中,模型需要在没有任何标注的情况下自动找到图像中的主要物体。DINOv3在VOC2007数据集上达到了66.1%的CorLoc,这个成绩表明它具有很强的自主理解能力。
为了验证模型的实际应用价值,研究团队还进行了大量的复杂系统测试。在目标检测任务中,使用冻结的DINOv3作为特征提取器的系统达到了66.1%的mAP,创造了新的记录。在语义分割任务中,基于DINOv3的系统在ADE20k数据集上达到了63.0%的mIoU,达到了当前最先进的水平。
这些全面的评估结果表明,DINOv3不仅在理论上具有先进性,在实际应用中也具有很高的价值。它就像一个全能型的人才,无论在哪个领域都能展现出专业水准的表现。
七、突破传统边界:从自然图像到专业领域的全面适应
DINOv3最令人印象深刻的特质之一是它超越传统视觉AI局限性的能力。大多数计算机视觉模型就像专业技术人员,只能在特定领域发挥作用,一旦离开熟悉的环境就表现平平。而DINOv3更像一个具有通用智慧的学者,无论面对什么样的视觉内容都能快速理解并做出准确判断。
在地理遥感领域,DINOv3展现出了令人惊叹的适应能力。研究团队专门训练了一个针对卫星图像的DINOv3变体,使用了4.93亿张卫星图像进行训练。这个模型就像一个从太空视角观察地球的专家,能够准确分析地表的各种特征。在森林冠层高度估计任务中,这个模型的表现超越了所有现有方法,平均绝对误差降低到了2.02米,这个精度对于森林管理和碳储量评估具有重要价值。
更有趣的是,即使是在自然图像上训练的通用DINOv3模型,在处理卫星图像时也表现出了令人惊讶的能力。这种跨域适应能力说明DINOv3学到的不是简单的图像模式,而是更深层的视觉理解原理。就像一个优秀的艺术家,无论使用什么样的画布和颜料都能创作出出色的作品。
在医学图像分析领域,虽然论文中没有详细展开,但研究团队提到DINOv3在病理学图像分析中显示出了良好的潜力。这种跨领域的适应能力对于医学AI的发展具有重要意义,因为医学图像往往具有与自然图像完全不同的特征和模式。
艺术作品分析是另一个展现DINOv3跨领域能力的重要应用。在Met艺术品检索数据集上,DINOv3表现出了对艺术作品的深度理解能力。它不仅能识别艺术品中的具体物体,还能理解艺术风格、构图方式等更抽象的视觉元素。这种能力对于数字人文学科研究、艺术品数字化管理等应用具有重要价值。
在工业检测领域,DINOv3的高精度特征提取能力为质量控制和缺陷检测提供了新的可能性。虽然工业图像往往具有与自然图像截然不同的特征,但DINOv3强大的泛化能力使其能够快速适应这些新的视觉环境。
历史图像分析是DINOv3展现其时间适应性的有趣应用。在AmsterTime数据集中,模型需要在现代街景图像和历史档案图像之间建立对应关系。这个任务不仅要求模型理解空间关系,还要能够跨越时间的变化。DINOv3在这个任务上达到了56.5%的mAP,显著超越了其他方法。
更令人惊叹的是DINOv3在不同分辨率下的稳定表现。从低分辨率的网络图片到超高分辨率的专业摄影作品,DINOv3都能保持一致的理解质量。研究团队展示了模型处理4096×4096像素超高分辨率图像的能力,这种分辨率适应性对于需要精细分析的专业应用具有重要价值。
在多模态理解方面,研究团队还开发了一个与文本对齐的DINOv3变体。这个模型不仅能理解图像,还能将视觉理解与文本描述联系起来。在开放词汇语义分割任务中,这个模型在ADE20k数据集上达到了24.7%的mIoU,在Cityscapes数据集上达到了36.9%的mIoU,这些成绩在密集文本对齐任务中是相当出色的。
DINOv3的这种跨领域适应能力不是偶然的,而是其自监督学习方法的必然结果。通过学习图像的内在结构和关系,而不是依赖特定的标注信息,DINOv3获得了一种更加通用和深层的视觉理解能力。这种能力使其能够像人类视觉系统一样,快速适应新的视觉环境和任务。
八、技术影响与未来展望:重新定义视觉人工智能的边界
DINOv3的成功不仅仅是一个单独的技术突破,它更像是为整个计算机视觉领域点亮了一盏明灯,照亮了未来发展的方向。这项研究的影响力远远超出了学术界,正在重新定义人们对视觉人工智能可能性的认知。
从技术发展的角度来看,DINOv3证明了自监督学习在视觉理解领域的巨大潜力。传统的监督学习方法就像培养专业技术工人,需要大量的标注数据和针对性训练。而DINOv3展示的自监督学习方法更像是培养通才,通过观察和思考获得广泛的理解能力。这种转变对整个AI行业具有深远意义。
在数据效率方面,DINOv3的成功为解决数据标注成本高昂的问题提供了新思路。传统的监督学习需要人工标注大量数据,这个过程既耗时又昂贵,特别是在医学、遥感等专业领域。DINOv3证明了仅通过观察原始图像就能学到有价值的知识,这为利用互联网上的海量未标注图像开辟了新的可能性。
模型可扩展性是DINOv3带来的另一个重要启示。通过知识蒸馏技术,研究团队成功地将70亿参数大模型的知识传递给了各种规模的小模型。这种"一次训练,多次部署"的模式为AI技术的产业化应用提供了高效的解决方案。就像一个优秀的教学体系,既有顶尖的研究型大学,也有各种层次的教育机构。
在计算效率方面,DINOv3展示了如何通过巧妙的设计来平衡性能和效率。Gram锚定技术不仅解决了大规模训练中的技术难题,还为其他研究提供了重要的方法论参考。这种技术创新对于推动AI技术在资源受限环境中的应用具有重要价值。
跨领域适应能力是DINOv3最令人兴奋的特性之一。从自然图像到卫星遥感,从艺术作品到医学影像,DINOv3展现出的广泛适应性为AI技术在各个垂直领域的应用提供了新的可能性。这种通用性将大大降低AI技术在新领域应用的门槛。
对于产业应用而言,DINOv3的影响可能是革命性的。在自动驾驶领域,DINOv3的三维理解能力和跨环境适应性为开发更安全、更可靠的自动驾驶系统提供了新工具。在医疗诊断领域,其强大的特征提取能力可能帮助医生更准确地分析医学图像。在内容创作领域,DINOv3的图像理解能力可能催生新的创意工具和应用。
然而,这项技术的发展也带来了一些需要关注的问题。首先是计算资源的需求。虽然研究团队提供了各种规模的模型,但要充分发挥DINOv3的能力仍需要相当的计算资源。这可能会加剧AI技术发展中的资源不平等问题。
环境影响是另一个需要考虑的因素。训练DINOv3这样的大规模模型需要消耗大量能源,研究团队估计整个项目的碳排放量约为2600吨二氧化碳当量。虽然这个数字在AI研究中并不算特别高,但随着这类技术的普及,环境影响问题需要得到更多关注。
数据隐私和伦理问题也值得深思。DINOv3的训练使用了大量从互联网收集的图像,这些图像的使用权限和隐私保护问题需要仔细考虑。特别是当这种技术被用于人脸识别、监控等敏感应用时,需要建立完善的伦理和法律框架。
展望未来,DINOv3的成功可能催生更多的技术创新。我们可能会看到更大规模的自监督学习模型,更高效的知识蒸馏方法,以及更好的跨模态理解能力。同时,这种技术也可能推动硬件的发展,促进更高效的AI计算芯片的研发。
在应用层面,我们可以预期DINOv3技术将很快出现在各种实际产品中。从智能手机的拍照功能到专业的图像分析软件,从自动驾驶汽车到医疗诊断设备,DINOv3的影响将无处不在。
最重要的是,DINOv3为我们展示了一种全新的AI发展路径。它证明了通过模仿人类的学习方式,AI系统可以获得更加通用和强大的能力。这种启示可能不仅适用于视觉理解,还可能推广到其他AI领域,为构建真正智能的AI系统提供新的思路。
说到底,DINOv3不仅仅是一个技术成果,更是人工智能发展史上的一个重要里程碑。它向我们展示了AI技术的无限可能,也提醒我们需要以更加负责任的态度来发展和应用这些强大的技术。随着这项技术的不断发展和完善,我们有理由相信,它将为人类社会带来更多积极的变化和进步。
对于那些对这项技术感兴趣的读者,可以通过论文编号arXiv:2508.10104v1查询完整的技术细节。这项由Meta AI研究院领导的突破性工作,不仅推动了学术研究的前沿,也为整个AI产业的发展指明了新的方向。在人工智能快速发展的今天,像DINOv3这样的技术创新让我们对未来充满期待。
Q&A
Q1:DINOv3是什么?它和传统的人工智能视觉模型有什么不同?
A:DINOv3是Meta AI研究院开发的一种自监督学习视觉模型,最大的不同在于它不需要人工标注的数据就能学会理解图像。传统模型像专业技术工人,需要大量标注数据训练,而DINOv3更像通才,仅通过观察16.89亿张未标注图片就学会了识别和理解各种视觉内容,在目标检测、图像分割等多个任务上都达到了业界最高水平。
Q2:什么是Gram锚定技术?它解决了什么问题?
A:Gram锚定是DINOv3的核心技术创新,解决了大规模模型训练中的一个重要难题。研究团队发现,随着训练时间延长,虽然模型整体识别能力提升,但对图像细节的关注度会下降。Gram锚定就像给模型设置"细节提醒器",定期让它回顾早期学到的精细特征,确保在学习新知识时不忘记对细节的敏感度,从而同时保持全局理解和局部精度。
Q3:DINOv3有哪些实际应用?普通人能用到吗?
A:DINOv3的应用非常广泛,包括自动驾驶的视觉识别、医学图像分析、卫星遥感图像处理、艺术品数字化管理等。对普通人来说,这项技术很可能很快出现在智能手机拍照功能、图片编辑软件、视频内容分析等日常应用中。研究团队还开发了不同规模的模型版本,从适合手机使用的小型模型到服务器级的大型模型,让各种设备都能受益于这项技术。
更新内容
一、修复bug,修改自动播放;优化产品用户体验。
二、 1.修复已知Bug。2.新服务。
三、修复已知bug;优化用户体验
四、1,交互全面优化,用户操作更加便捷高效;2,主题色更新,界面风格更加协调;3,增加卡片类个人数据
五、-千万商品随意挑选,大图展现商品细节-订单和物流查询实时同步-支持团购和名品特卖,更有手机专享等你抢-支付宝和银联多种支付方式,轻松下单,快捷支付-新浪微博,支付宝,QQ登录,不用注册也能购物-支持商品收藏,随时查询喜爱的商品和历史购物清单。
六、1.bug修复,提升用户体验;2.优化加载,体验更流程;3.提升安卓系统兼容性
七、1、修复部分机型bug;2、提高游戏流畅度;
厂商其他下载
安卓应用 安卓手游 苹果应用 苹果手游 电脑 更多+
-
 盘锦一养殖户数万斤罗氏虾一夜冻死
盘锦一养殖户数万斤罗氏虾一夜冻死
-
 十个勤天新专辑
十个勤天新专辑
-
 消息称宗馥莉辞职因商标不合规
消息称宗馥莉辞职因商标不合规
-
 王青不要因为我影响冯建宇
王青不要因为我影响冯建宇
-
 白鹿月生病瘦到斤
白鹿月生病瘦到斤
-
 全球每人就有人患精神疾病
全球每人就有人患精神疾病
-
 建议早餐吃点高热量食物
建议早餐吃点高热量食物
-
 肖战直播
肖战直播
-
 人唯一不会长大的器官
人唯一不会长大的器官
-
 商务部回应对美国船舶收取特别港务费
商务部回应对美国船舶收取特别港务费
-
 人唯一不会长大的器官
人唯一不会长大的器官
-
 新华社评小米对标苹果
新华社评小米对标苹果
-
 人唯一不会长大的器官
人唯一不会长大的器官
-
 陈伟霆早期严选的权威性
陈伟霆早期严选的权威性
-
 王青回应
王青回应
-
 王青回应
王青回应
-
 全球每人就有人患精神疾病
全球每人就有人患精神疾病
-
 山西一车站售票员上班刷手机被调岗
山西一车站售票员上班刷手机被调岗
-
 建议早餐吃点高热量食物
建议早餐吃点高热量食物
-
 美对中国船舶收费中方对美同时实施
美对中国船舶收费中方对美同时实施
相关版本
- 中文名:Meta AI研究院DINOv3:实现类人视觉识别能力
- 包名:com.ejiaqrp.dtgen
- MD5:P7ENQIWOC1RTO1T6EP
查看所有 0条评论>网友评论
- 相关游戏
-
 山姆大疆补偿方案
山姆大疆补偿方案
 石破茂称日政府从未否认侵略战争
石破茂称日政府从未否认侵略战争
 山西一车站售票员上班刷手机被调岗
山西一车站售票员上班刷手机被调岗
 日本母亲杀死女儿冰箱藏尸年
日本母亲杀死女儿冰箱藏尸年
 委内瑞拉说美国可能很快会动武
委内瑞拉说美国可能很快会动武
 石破茂称日政府从未否认侵略战争
石破茂称日政府从未否认侵略战争
 向华强隆重的辟谣方式
向华强隆重的辟谣方式
 费德勒甄子丹郑洁吴磊
费德勒甄子丹郑洁吴磊
 美对中国船舶收费中方对美同时实施
美对中国船舶收费中方对美同时实施
 石破茂称日政府从未否认侵略战争
石破茂称日政府从未否认侵略战争
 新华社评小米对标苹果
新华社评小米对标苹果
 徒步高反失温女生不排除植物人风险
徒步高反失温女生不排除植物人风险
 向华强发声明回应向家破产
向华强发声明回应向家破产
 成龙演唱故宫百年主题曲
成龙演唱故宫百年主题曲
 山姆回应门店大疆产品降价
山姆回应门店大疆产品降价
 石破茂称日政府从未否认侵略战争
石破茂称日政府从未否认侵略战争
 山姆回应门店大疆产品降价
山姆回应门店大疆产品降价
 第一次觉得曲筱绡的刻薄恰到好处
第一次觉得曲筱绡的刻薄恰到好处
 推动中朝关系不断向前发展
推动中朝关系不断向前发展
 山姆大疆补偿方案
山姆大疆补偿方案
 十个勤天新专辑
十个勤天新专辑
 推动中朝关系不断向前发展
推动中朝关系不断向前发展
 纳斯达克
纳斯达克
 费德勒甄子丹郑洁吴磊
费德勒甄子丹郑洁吴磊
 全球每人就有人患精神疾病
全球每人就有人患精神疾病
 新华社评小米对标苹果
新华社评小米对标苹果
 要是我这样三天不敢看微信
要是我这样三天不敢看微信
 消息称宗馥莉辞职因商标不合规
消息称宗馥莉辞职因商标不合规
 要是我这样三天不敢看微信
要是我这样三天不敢看微信
 山西一车站售票员上班刷手机被调岗
山西一车站售票员上班刷手机被调岗
 女子洗完澡发现窗外无人机悬停
女子洗完澡发现窗外无人机悬停
 美对中国船舶收费中方对美同时实施
美对中国船舶收费中方对美同时实施
 费德勒甄子丹郑洁吴磊
费德勒甄子丹郑洁吴磊
 全国通办婚姻登记万余对
全国通办婚姻登记万余对
 白鹿月生病瘦到斤
白鹿月生病瘦到斤
 新华社评小米对标苹果
新华社评小米对标苹果
 商务部回应对美国船舶收取特别港务费
商务部回应对美国船舶收取特别港务费
 日本母亲杀死女儿冰箱藏尸年
日本母亲杀死女儿冰箱藏尸年
 视界大会年度推荐整花活了
视界大会年度推荐整花活了
 消息称宗馥莉辞职因商标不合规
消息称宗馥莉辞职因商标不合规
- 更多>心动网络手游
-
 周深新歌重光
周深新歌重光
 全球每人就有人患精神疾病
全球每人就有人患精神疾病
 第一次觉得曲筱绡的刻薄恰到好处
第一次觉得曲筱绡的刻薄恰到好处
 日本首相选举出现黑马
日本首相选举出现黑马
 石破茂称日政府从未否认侵略战争
石破茂称日政府从未否认侵略战争
 中方一个个点名多个国家劣迹
中方一个个点名多个国家劣迹
 消息称宗馥莉辞职因商标不合规
消息称宗馥莉辞职因商标不合规
 朝鲜迎建党周年
朝鲜迎建党周年
 女子洗完澡发现窗外无人机悬停
女子洗完澡发现窗外无人机悬停
 全球每人就有人患精神疾病
全球每人就有人患精神疾病
 委内瑞拉说美国可能很快会动武
委内瑞拉说美国可能很快会动武
 美股
美股
 美股
美股
 王青不要因为我影响冯建宇
王青不要因为我影响冯建宇
 美股跳水
美股跳水
 要是我这样三天不敢看微信
要是我这样三天不敢看微信
 白鹿说自己得了疑难杂症
白鹿说自己得了疑难杂症
 山西一车站售票员上班刷手机被调岗
山西一车站售票员上班刷手机被调岗
 中方一个个点名多个国家劣迹
中方一个个点名多个国家劣迹
 美股
美股
 视界大会年度推荐整花活了
视界大会年度推荐整花活了
 美股跳水
美股跳水
 白鹿月生病瘦到斤
白鹿月生病瘦到斤
 美股跳水
美股跳水
 山姆大疆补偿方案
山姆大疆补偿方案
 许我耀眼名场面张翰娜扎官宣图
许我耀眼名场面张翰娜扎官宣图
 委内瑞拉说美国可能很快会动武
委内瑞拉说美国可能很快会动武
 事业单位公众号停更年变色情链接
事业单位公众号停更年变色情链接
 向华强发声明回应向家破产
向华强发声明回应向家破产
 盘锦一养殖户数万斤罗氏虾一夜冻死
盘锦一养殖户数万斤罗氏虾一夜冻死
 人唯一不会长大的器官
人唯一不会长大的器官
 委内瑞拉说美国可能很快会动武
委内瑞拉说美国可能很快会动武
 要是我这样三天不敢看微信
要是我这样三天不敢看微信
 建议早餐吃点高热量食物
建议早餐吃点高热量食物
 石破茂称日政府从未否认侵略战争
石破茂称日政府从未否认侵略战争
 十个勤天新专辑
十个勤天新专辑
 全国通办婚姻登记万余对
全国通办婚姻登记万余对
 委内瑞拉说美国可能很快会动武
委内瑞拉说美国可能很快会动武
 张远终于不做嘉宾做新郎了
张远终于不做嘉宾做新郎了
 新华社评小米对标苹果
新华社评小米对标苹果
- 更多>mod游戏
-
 肖战直播
肖战直播
 澳门之约
澳门之约
 周深新歌重光
周深新歌重光
 许我耀眼名场面张翰娜扎官宣图
许我耀眼名场面张翰娜扎官宣图
 委内瑞拉说美国可能很快会动武
委内瑞拉说美国可能很快会动武
 美股
美股
 白鹿月生病瘦到斤
白鹿月生病瘦到斤
 白鹿月生病瘦到斤
白鹿月生病瘦到斤
 白鹿月生病瘦到斤
白鹿月生病瘦到斤
 战胜狼队
战胜狼队
 视界大会年度推荐整花活了
视界大会年度推荐整花活了
 视界大会推荐送花还是送瓜
视界大会推荐送花还是送瓜
 纳斯达克
纳斯达克
 关晓彤少喝点吧
关晓彤少喝点吧
 向华强隆重的辟谣方式
向华强隆重的辟谣方式
 资助了年的妹妹第一笔工资给了我
资助了年的妹妹第一笔工资给了我
 许我耀眼名场面张翰娜扎官宣图
许我耀眼名场面张翰娜扎官宣图
 全国通办婚姻登记万余对
全国通办婚姻登记万余对
 吴磊费德勒网球对打
吴磊费德勒网球对打
 款吉利星愿万元起
款吉利星愿万元起
 许我耀眼名场面张翰娜扎官宣图
许我耀眼名场面张翰娜扎官宣图
 成龙演唱故宫百年主题曲
成龙演唱故宫百年主题曲
 推动中朝关系不断向前发展
推动中朝关系不断向前发展
 山西一车站售票员上班刷手机被调岗
山西一车站售票员上班刷手机被调岗
 公主皇冠
公主皇冠
 向华强隆重的辟谣方式
向华强隆重的辟谣方式
 费德勒甄子丹郑洁吴磊
费德勒甄子丹郑洁吴磊
 关晓彤少喝点吧
关晓彤少喝点吧
 成龙演唱故宫百年主题曲
成龙演唱故宫百年主题曲
 全球每人就有人患精神疾病
全球每人就有人患精神疾病
 日本首相选举出现黑马
日本首相选举出现黑马
 费德勒甄子丹郑洁吴磊
费德勒甄子丹郑洁吴磊
 十个勤天新专辑
十个勤天新专辑
 徒步高反失温女生不排除植物人风险
徒步高反失温女生不排除植物人风险
 第一次觉得曲筱绡的刻薄恰到好处
第一次觉得曲筱绡的刻薄恰到好处
 朝鲜迎建党周年
朝鲜迎建党周年
 第一次觉得曲筱绡的刻薄恰到好处
第一次觉得曲筱绡的刻薄恰到好处
 白鹿月生病瘦到斤
白鹿月生病瘦到斤
 向华强隆重的辟谣方式
向华强隆重的辟谣方式
 山姆回应门店大疆产品降价
山姆回应门店大疆产品降价
- 更多>像素rpg游戏
-
 视界大会年度推荐整花活了
视界大会年度推荐整花活了
 要是我这样三天不敢看微信
要是我这样三天不敢看微信
 周深新歌重光
周深新歌重光
 成龙演唱故宫百年主题曲
成龙演唱故宫百年主题曲
 消息称宗馥莉辞职因商标不合规
消息称宗馥莉辞职因商标不合规
 十个勤天新专辑
十个勤天新专辑
 宗馥莉仍是娃哈哈第二大股东
宗馥莉仍是娃哈哈第二大股东
 陈伟霆早期严选的权威性
陈伟霆早期严选的权威性
 肖战直播
肖战直播
 美股
美股
 视界大会年度推荐整花活了
视界大会年度推荐整花活了
 日本母亲杀死女儿冰箱藏尸年
日本母亲杀死女儿冰箱藏尸年
 山西一车站售票员上班刷手机被调岗
山西一车站售票员上班刷手机被调岗
 吴磊费德勒网球对打
吴磊费德勒网球对打
 徒步高反失温女生不排除植物人风险
徒步高反失温女生不排除植物人风险
 白鹿说自己得了疑难杂症
白鹿说自己得了疑难杂症
 商务部回应对美国船舶收取特别港务费
商务部回应对美国船舶收取特别港务费
 视界大会年度推荐整花活了
视界大会年度推荐整花活了
 白鹿月生病瘦到斤
白鹿月生病瘦到斤
 肖战直播
肖战直播
 徒步高反失温女生不排除植物人风险
徒步高反失温女生不排除植物人风险
 宗馥莉仍是娃哈哈第二大股东
宗馥莉仍是娃哈哈第二大股东
 美对中国船舶收费中方对美同时实施
美对中国船舶收费中方对美同时实施
 石破茂称日政府从未否认侵略战争
石破茂称日政府从未否认侵略战争
 中方一个个点名多个国家劣迹
中方一个个点名多个国家劣迹
 商务部回应对美国船舶收取特别港务费
商务部回应对美国船舶收取特别港务费
 成龙演唱故宫百年主题曲
成龙演唱故宫百年主题曲
 全国通办婚姻登记万余对
全国通办婚姻登记万余对
 澳门之约
澳门之约
 女子洗完澡发现窗外无人机悬停
女子洗完澡发现窗外无人机悬停
 建议早餐吃点高热量食物
建议早餐吃点高热量食物
 美股跳水
美股跳水
 消息称宗馥莉辞职因商标不合规
消息称宗馥莉辞职因商标不合规
 张远终于不做嘉宾做新郎了
张远终于不做嘉宾做新郎了
 人唯一不会长大的器官
人唯一不会长大的器官
 王青回应
王青回应
 日本首相选举出现黑马
日本首相选举出现黑马
 委内瑞拉说美国可能很快会动武
委内瑞拉说美国可能很快会动武
 冯建宇直播
冯建宇直播
 陈伟霆早期严选的权威性
陈伟霆早期严选的权威性
-
2025-10-11
1

-
2025-10-11
2

-
2025-10-11
3

-
2025-10-11
4

-
2025-10-11
5

-
2025-10-11
6

-
2025-10-11
7

-
2025-10-11
8

-
2025-10-11
9

-
2025-10-11
10

-
2025-10-11
11

-
2025-10-11
12

-
2025-10-11
13

-
2025-10-11
14

-
2025-10-11
15

-
2025-10-11
16

-
2025-10-11
17

-
2025-10-11
18

-
2025-10-11
19

-
2025-10-11
20

-
2025-10-11
21

-
2025-10-11
22

-
2025-10-11
23

-
2025-10-11
24

-
2025-10-11
25

-
2025-10-11
26

-
2025-10-11
27

-
2025-10-11
28

-
2025-10-11
29

-
2025-10-11
30

-
2025-10-11
31

-
2025-10-11
32

-
2025-10-11
33

-
2025-10-11
34

-
2025-10-11
35

-
2025-10-11
36

-
2025-10-11
37

-
2025-10-11
38

-
2025-10-11
39

-
2025-10-11
40

-
2025-10-11
41

-
2025-10-11
42

-
2025-10-11
43

-
2025-10-11
44
-
2025-10-11
45

-
2025-10-11
46

-
2025-10-11
47

-
2025-10-11
48

-
2025-10-11
49

-
2025-10-11
50

-
2025-10-11
51

-
2025-10-11
52

-
2025-10-11
53

-
2025-10-11
54

-
2025-10-11
55

-
2025-10-11
56

-
2025-10-11
57

-
2025-10-11
58

-
2025-10-11
59

-
2025-10-11
60

-
2025-10-11
61

-
2025-10-11
62

-
2025-10-11
63

-
2025-10-11
64

-
2025-10-11
65

-
2025-10-11
66

-
2025-10-11
67

-
2025-10-11
68

-
2025-10-11
69

-
2025-10-11
70
-
2025-10-11
71

-
2025-10-11
72

-
2025-10-11
73
-
2025-10-11
74

-
2025-10-11
75

-
2025-10-11
76

-
2025-10-11
77

-
2025-10-11
78

-
2025-10-11
79

-
2025-10-11
80

-
2025-10-11
81

-
2025-10-11
82

-
2025-10-11
83

-
2025-10-11
84

-
2025-10-11
85

-
2025-10-11
86

-
2025-10-11
87

-
2025-10-11
88

-
2025-10-11
89

-
2025-10-11
90

-
2025-10-11
91

-
2025-10-11
92

-
2025-10-11
93

-
2025-10-11
94

-
2025-10-11
95

-
2025-10-11
96

-
2025-10-11
97

-
2025-10-11
98

-
2025-10-11
99

-
2025-10-11
100

-
2025-10-11
101

-
2025-10-11
102

-
2025-10-11
103

-
2025-10-11
104

-
2025-10-11
105

-
2025-10-11
106

-
2025-10-11
107

-
2025-10-11
108

-
2025-10-11
109
-
2025-10-11
110

-
2025-10-11
111

-
2025-10-11
112

-
2025-10-11
113

-
2025-10-11
114

-
2025-10-11
115

-
2025-10-11
116

-
2025-10-11
117
-
2025-10-11
118

-
2025-10-11
119

-
2025-10-11
120

-
2025-10-11
121

-
2025-10-11
122
-
2025-10-11
123

-
2025-10-11
124

-
2025-10-11
125

-
2025-10-11
126

-
2025-10-11
127

-
2025-10-11
128

-
2025-10-11
129

-
2025-10-11
130

-
2025-10-11
131

-
2025-10-11
132

-
2025-10-11
133

-
2025-10-11
134

-
2025-10-11
135
-
2025-10-11
136

-
2025-10-11
137

-
2025-10-11
138

-
2025-10-11
139

-
2025-10-11
140

-
2025-10-11
141
-
2025-10-11
142

-
2025-10-11
143

-
2025-10-11
144

-
2025-10-11
145

-
2025-10-11
146

-
2025-10-11
147

-
2025-10-11
148

-
2025-10-11
149

-
2025-10-11
150

-
2025-10-11
151
-
2025-10-11
152

-
2025-10-11
153

-
2025-10-11
154

-
2025-10-11
155

-
2025-10-11
156

-
2025-10-11
157

-
2025-10-11
158

-
2025-10-11
159

-
2025-10-11
160

-
2025-10-11
161

-
2025-10-11
162

-
2025-10-11
163

-
2025-10-11
164

-
2025-10-11
165

-
2025-10-11
166

-
2025-10-11
167

-
2025-10-11
168

-
2025-10-11
169

-
2025-10-11
170

-
2025-10-11
171

-
2025-10-11
172

-
2025-10-11
173
-
2025-10-11
174

-
2025-10-11
175

-
2025-10-11
176

-
2025-10-11
177

-
2025-10-11
178

-
2025-10-11
179

-
2025-10-11
180

-
2025-10-11
181

-
2025-10-11
182

-
2025-10-11
183

-
2025-10-11
184

-
2025-10-11
185

-
2025-10-11
186

-
2025-10-11
187

-
2025-10-11
188

-
2025-10-11
189
-
2025-10-11
190

-
2025-10-11
191

-
2025-10-11
192

-
2025-10-11
193

-
2025-10-11
194

-
2025-10-11
195

-
2025-10-11
196

-
2025-10-11
197

-
2025-10-11
198

-
2025-10-11
199

-
2025-10-11
200

-
2025-10-11
201

-
2025-10-11
202
-
2025-10-11
203
-
2025-10-11
204

-
2025-10-11
205

-
2025-10-11
206

-
2025-10-11
207

-
2025-10-11
208

-
2025-10-11
209

-
2025-10-11
210

-
2025-10-11
211

-
2025-10-11
212

-
2025-10-11
213

-
2025-10-11
214

-
2025-10-11
215

-
2025-10-11
216

-
2025-10-11
217

-
2025-10-11
218

-
2025-10-11
219

-
2025-10-11
220

-
2025-10-11
221

-
2025-10-11
222

-
2025-10-11
223

-
2025-10-11
224

-
2025-10-11
225

-
2025-10-11
226

-
2025-10-11
227

-
2025-10-11
228

-
2025-10-11
229
-
2025-10-11
230
-
2025-10-11
231

-
2025-10-11
232

-
2025-10-11
233

-
2025-10-11
234

-
2025-10-11
235

-
2025-10-11
236

-
2025-10-11
237

-
2025-10-11
238

-
2025-10-11
239

-
2025-10-11
240

-
2025-10-11
241

-
2025-10-11
242

-
2025-10-11
243

-
2025-10-11
244

-
2025-10-11
245

-
2025-10-11
246

-
2025-10-11
247

-
2025-10-11
248

-
2025-10-11
249

-
2025-10-11
250

-
2025-10-11
251

-
2025-10-11
252

-
2025-10-11
253

-
2025-10-11
254

-
2025-10-11
255

-
2025-10-11
256

-
2025-10-11
257

-
2025-10-11
258

-
2025-10-11
259

-
2025-10-11
260

-
2025-10-11
261

-
2025-10-11
262

-
2025-10-11
263

-
2025-10-11
264

-
2025-10-11
265

-
2025-10-11
266

-
2025-10-11
267

-
2025-10-11
268

-
2025-10-11
269

-
2025-10-11
270

-
2025-10-11
271

-
2025-10-11
272

-
2025-10-11
273

-
2025-10-11
274

-
2025-10-11
275

-
2025-10-11
276

-
2025-10-11
277
-
2025-10-11
278
-
2025-10-11
279

-
2025-10-11
280

-
2025-10-11
281

-
2025-10-11
282

-
2025-10-11
283

-
2025-10-11
284

-
2025-10-11
285

-
2025-10-11
286

-
2025-10-11
287

-
2025-10-11
288

-
2025-10-11
289

-
2025-10-11
290

-
2025-10-11
291

-
2025-10-11
292

-
2025-10-11
293
-
2025-10-11
294

-
2025-10-11
295

-
2025-10-11
296

-
2025-10-11
297

-
2025-10-11
298
-
2025-10-11
299

-
2025-10-11
300

-
2025-10-11
301

-
2025-10-11
302

-
2025-10-11
303

-
2025-10-11
304

-
2025-10-11
305

-
2025-10-11
306

-
2025-10-11
307

-
2025-10-11
308

-
2025-10-11
309

-
2025-10-11
310

-
2025-10-11
311

-
2025-10-11
312

-
2025-10-11
313

-
2025-10-11
314

-
2025-10-11
315

-
2025-10-11
316

-
2025-10-11
317

-
2025-10-11
318

-
2025-10-11
319

-
2025-10-11
320

-
2025-10-11
321

-
2025-10-11
322

-
2025-10-11
323

-
2025-10-11
324

-
2025-10-11
325

-
2025-10-11
326

-
2025-10-11
327

-
2025-10-11
328

-
2025-10-11
329

-
2025-10-11
330
-
2025-10-11
331

-
2025-10-11
332

-
2025-10-11
333

-
2025-10-11
334

-
2025-10-11
335
-
2025-10-11
336

-
2025-10-11
337

-
2025-10-11
338

-
2025-10-11
339

-
2025-10-11
340

-
2025-10-11
341

-
2025-10-11
342

-
2025-10-11
343

-
2025-10-11
344

-
2025-10-11
345

-
2025-10-11
346

-
2025-10-11
347

-
2025-10-11
348

-
2025-10-11
349

-
2025-10-11
350

-
2025-10-11
351

-
2025-10-11
352

-
2025-10-11
353

-
2025-10-11
354

-
2025-10-11
355

-
2025-10-11
356
-
2025-10-11
357
-
2025-10-11
358

-
2025-10-11
359

-
2025-10-11
360

-
2025-10-11
361

-
2025-10-11
362

-
2025-10-11
363

-
2025-10-11
364
-
2025-10-11
365

-
2025-10-11
366
-
2025-10-11
367

-
2025-10-11
368

-
2025-10-11
369

-
2025-10-11
370

-
2025-10-11
371

-
2025-10-11
372

-
2025-10-11
373

-
2025-10-11
374

-
2025-10-11
375

-
2025-10-11
376

-
2025-10-11
377

-
2025-10-11
378

-
2025-10-11
379

-
2025-10-11
380

-
2025-10-11
381

-
2025-10-11
382

-
2025-10-11
383

-
2025-10-11
384

-
2025-10-11
385
-
2025-10-11
386

-
2025-10-11
387

-
2025-10-11
388
-
2025-10-11
389

-
2025-10-11
390

-
2025-10-11
391

-
2025-10-11
392

-
2025-10-11
393

-
2025-10-11
394

-
2025-10-11
395

-
2025-10-11
396

-
2025-10-11
397

-
2025-10-11
398

-
2025-10-11
399
-
2025-10-11
400

-
2025-10-11
1

-
2025-10-11
2
-
2025-10-11
3
-
2025-10-11
4

-
2025-10-11
5

-
2025-10-11
6

-
2025-10-11
7

-
2025-10-11
8

-
2025-10-11
9

-
2025-10-11
10

-
2025-10-11
11

-
2025-10-11
12

-
2025-10-11
13

-
2025-10-11
14
-
2025-10-11
15
-
2025-10-11
16

-
2025-10-11
17

-
2025-10-11
18

-
2025-10-11
19
-
2025-10-11
20

-
2025-10-11
21

-
2025-10-11
22

-
2025-10-11
23

-
2025-10-11
24

-
2025-10-11
25

-
2025-10-11
26

-
2025-10-11
27

-
2025-10-11
28

-
2025-10-11
29

-
2025-10-11
30

-
2025-10-11
31

-
2025-10-11
32

-
2025-10-11
33

-
2025-10-11
34

-
2025-10-11
35

-
2025-10-11
36

-
2025-10-11
37

-
2025-10-11
38

-
2025-10-11
39

-
2025-10-11
40

-
2025-10-11
41

-
2025-10-11
42

-
2025-10-11
43

-
2025-10-11
44

-
2025-10-11
45

-
2025-10-11
46

-
2025-10-11
47

-
2025-10-11
48

-
2025-10-11
49

-
2025-10-11
50

-
2025-10-11
51

-
2025-10-11
52

-
2025-10-11
53

-
2025-10-11
54

-
2025-10-11
55

-
2025-10-11
56
-
2025-10-11
57

-
2025-10-11
58

-
2025-10-11
59

-
2025-10-11
60

-
2025-10-11
61
-
2025-10-11
62

-
2025-10-11
63
-
2025-10-11
64

-
2025-10-11
65

-
2025-10-11
66

-
2025-10-11
67

-
2025-10-11
68

-
2025-10-11
69

-
2025-10-11
70

-
2025-10-11
71
-
2025-10-11
72

-
2025-10-11
73

-
2025-10-11
74

-
2025-10-11
75

-
2025-10-11
76

-
2025-10-11
77

-
2025-10-11
78
-
2025-10-11
79
-
2025-10-11
80

-
2025-10-11
81

-
2025-10-11
82

-
2025-10-11
83

-
2025-10-11
84

-
2025-10-11
85

-
2025-10-11
86

-
2025-10-11
87

-
2025-10-11
88

-
2025-10-11
89

-
2025-10-11
90

-
2025-10-11
91

-
2025-10-11
92

-
2025-10-11
93

-
2025-10-11
94

-
2025-10-11
95

-
2025-10-11
96

-
2025-10-11
97

-
2025-10-11
98

-
2025-10-11
99

-
2025-10-11
100

